思维重塑:搜索 vs 生成
AI 不是在数据库里找现成答案,它是基于概率预测下一个字。这意味着:“Garbage In, Garbage Out”(垃圾进,垃圾出) (GIGO)。
❌ 错误示范 (搜素引擎思维)
“帮我写论文。”(AI 会给你一篇平庸的泛泛而谈)
✔ 正确示范 (产品经理思维)
“你是一位社会学教授。请基于《乡土中国》的理论框架,为我列出三个关于‘现代城市化对传统家庭结构冲击’的论文选题方向,要求具有批判性思维。”
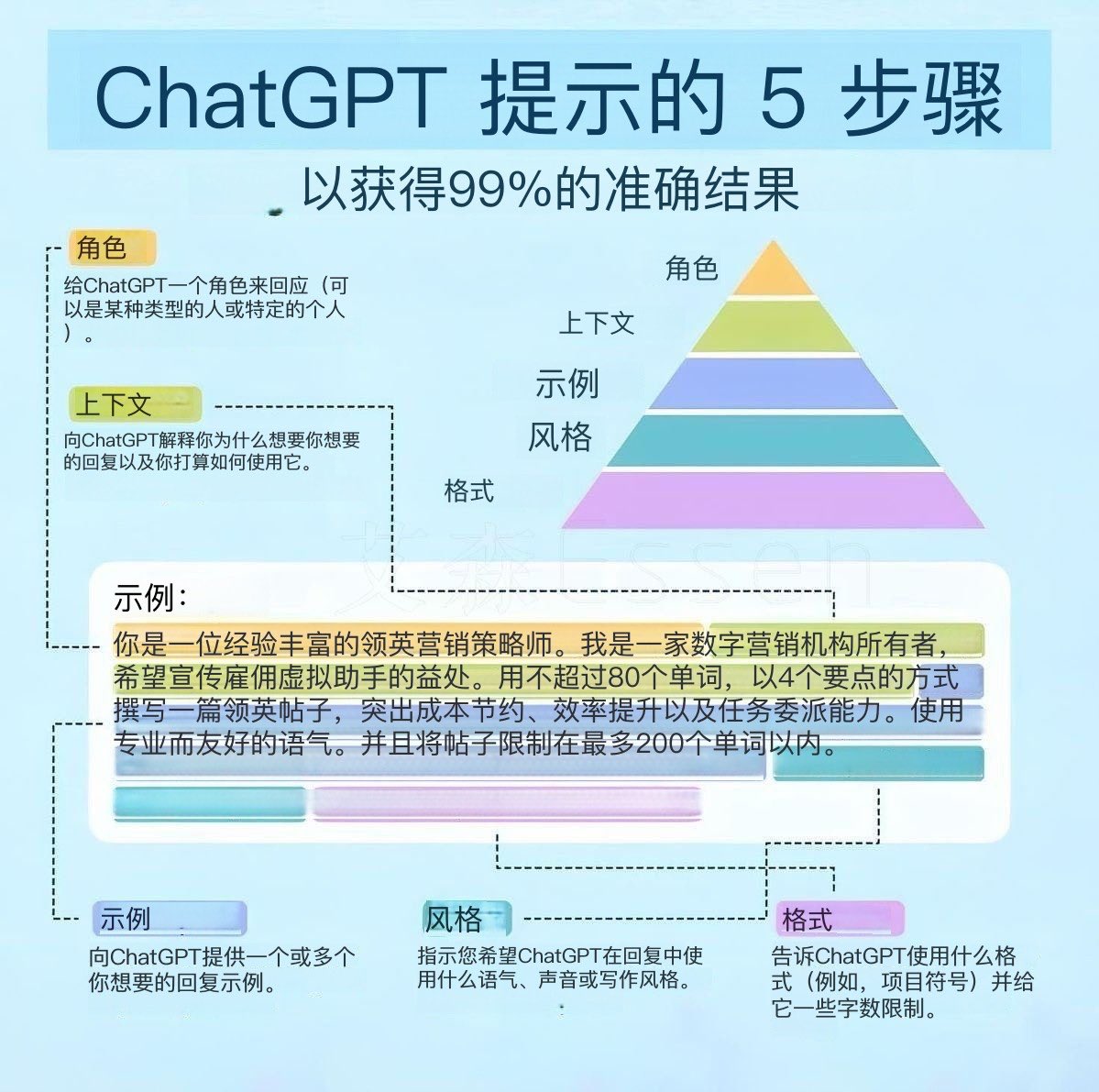
万能公式:R-C-T-F
一个完美的 Prompt 就像给实习生布置任务,必须要素齐全。套用这个公式,解决 90% 的问题。
Role
角色设定(激活模型特定领域的潜知识库)
“你是一个资深的 Python 专家...”
Context
背景信息(减少歧义,限定生成范围)
“我正在准备期末复习,时间只有2小时...”
Task
具体任务(使用强动词如:分析、总结、重写、代码实现等)
“请总结这篇文献的三个核心论点...”
Format
输出格式(降低阅读成本,直接可复用)
“用 Markdown、表格、JSON、像 Steve Jobs 的演讲风格...”
让 AI 变聪明的魔法
1. 举一反三 (Few-Shot)
不要只给指令,要给例子(Example)。
Prompt
将下列口语转换为学术用语。
例子:'这事儿挺难的' -> '该问题具有显著的复杂性'。
请转换:'我觉得这数据不对劲'。
例子:'这事儿挺难的' -> '该问题具有显著的复杂性'。
请转换:'我觉得这数据不对劲'。
2. 一步步思考 (Chain of Thought)
当你做数学题或逻辑题时,强制 AI 展示过程。
核心金句
“Let's think step by step.” (让我们一步步思考)
实战场景
- 阅读 文献辅助:
- “请用通俗语言总结这篇 PDF,并列出作者的 3 个核心假设。”
- "请扮演苏格拉底,针对我这篇论文的论点提出 3 个尖锐的反驳意见。"
- 编程 代码导师: “不要直接给代码。请解释为什么我这段 Python 会报错,并提供修复思路。”
- 求职 模拟面试: “我正在申请字节跳动的产品实习,请扮演面试官对我进行压力面试。”
- 写作 文字润色:
- “请作为雅思考官,给我的这篇作文打分,并指出词汇替换建议。”
- “请润色这封给导师的邮件,语气要专业、礼貌,但不要过于卑微。”
素养与红线
- 幻觉 (Hallucination): AI 会一本正经地胡说八道。涉及文献引用、事实数据,必须人工回查 (Trust but Verify);必须指定“不知道”: 告诉 AI:“如果你不知道答案,请直接说不知道,不要编造。”
- 隐私安全: 永远不要把身份证号、未发表的科研机密数据投喂给公共 AI。
- 学术诚信: 辅助 ≠ 代写。直接复制 AI 生成的内容作为作业是剽窃。